Extracting historical assay data with tesseract and python
- 4 minutes read - 775 wordsHi All,
I want to help you solve one of those occasional problematic issues that come up every now and then, extracting historical tabular data from old reports.
Let’s imagine that you’ve aquired a tenement and reading the historical reports it looks like you’re onto something great. But the only historical data that you have available is very old and unfortunately predates the nice digital formats that we have now.
This of course means that you can’t quickly go and make a sweet map of the anomaly run to the stock market and raise some funds for drilling and run a program.
Now you know you’re in for a few hours of pain, typing, checking, typing, checking… hundreds of lines that look like this

So follow along if you would like to save yourself a few hours.
Before we start ocr-ing we need to install tesseract to extract the text from the images and python to clean up the tesseract output
The first step is to install the required python libraries:
pip install pdfminer.six pytesseract pandas matplotlib
For this example we are going to use data from here the 1988 Jitarning Annual Report if you follow the link you can download the file manually or if you prefer you can run the below python script to do it for you.
import urllib.request
import os
import urllib.parse
import urllib.request
from pathlib import Path
import urllib.parse
import pdfminer
url = "https://geodocsget.dmirs.wa.gov.au/api/GeoDocsGet?filekey=696c1d6e-ecb2-4bc9-ac85-336a0fc8ac04-hqdh9cmzkqhxbe3192bfcholqvxhkfel182hnxss"
# this is the location that all the data will be saved to
# change this to something else if you prefer
outpath = Path('data/')
outfile = outpath.joinpath('A27066_a27066_a027066_pdf_(OCR).pdf')
# check if the folder exists if not make it
if not outpath.exists():
outpath.mkdir()
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url=url, headers=headers)
if not outfile.exists():
with urllib.request.urlopen(req) as response:
the_page = response.read()
with open(outfile,'wb') as file:
file.write(the_page)
print(f'{outfile} has been saved!')
else:
print(f'{outfile} already exists!')
Once we have the software installed and an example .pdf to play with we then need to extract each of the pages from your .pdf and save them to an image so that tesseract can deal with them.
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTPage
# borrowing the method outlined in this SO post to extract the images from the pdf
# https://stackoverflow.com/a/71110321
from pdfminer.image import ImageWriter
pages = list(extract_pages(outfile,page_numbers=range(23, 32)))
def get_image(layout_object):
if isinstance(layout_object, pdfminer.layout.LTImage):
return layout_object
if isinstance(layout_object, pdfminer.layout.LTContainer):
for child in layout_object:
return get_image(child)
else:
return None
def save_images_from_page(output_directory, page: LTPage):
images = list(filter(bool, map(get_image, page)))
iw = ImageWriter(output_directory)
for image in images:
iw.export_image(image)
for page in pages:
save_images_from_page(outpath,page)
We will now run the OCR software on the extracted images, using pytesseract and compile the extracted text into a text file for manipulation. Tesseract is very configurable but to extact these types of tabular formatted data you need to ensure that you are only allowing sensible characters and also the page segementation mode (psm) is set to 4 as this seems to work reliably on the text structure.
import pytesseract
# very important that you configure the tesseract options
tesseract_config = '-c tessedit_char_whitelist=".0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ " --psm 4'
ocr_string = []
for i in outpath.glob('*.bmp'):
tmp = pytesseract.image_to_string(str(i),config=tesseract_config)
ocr_string.append(tmp)
output_text = outpath.joinpath('ocr_extract.txt')
with open(output_text, 'w') as ff:
ff.writelines(ocr_string)
Now you can read in the file into excel or use regular expressions and pandas to only extract the columns that have been correctly recognised.
from matplotlib import pyplot as plt
import re
import pandas as pd
import numpy as np
# this is the regular expression that we are going to use
# to extract the data for each line.
re_parts = ['.*(?P<LineIdentifier>EDDY PYNE LINE [0-9A-Z.]{1,3})',
'.*(?P<Northing>[0-9]{7})',
'.*(?P<Easting>[0-9]{6})',
'.*(?P<SampleNo>[A-Z]{2} [0-9]{5})',
'.*(?P<SampleType>SUR[F|P]ACE PIT)',
'\s(?P<Au_AVG>[0-9OS]{1,4})']
re_final = ''.join(re_parts)
reg = re.compile(re_final)
# re-import the text dataset that we wrote out.
with open(output_text) as f:
tmp = f.readlines()
tmp_data = []
n_lines = len(tmp)
for j in tmp:
tm = reg.match(j)
if not tm is None:
td = tm.groupdict()
for t in td:
try:
# handle the case where numbers are misclassified
# as letters e.g O-0, S-5
tmp_text = td[t]
if t == 'Au_AVG':
# replace the letters with numbers and add the decimal
# place back
tmp_text = '.'+tmp_text.replace('O','0').replace('S','5')
print(f'{tmp_text}:{td[t]}')
td[t] = float(tmp_text)
except:
td[t] = tmp_text
tmp_data.append(td)
else:
# print out the lines that didn't properly fit the format
print(j)
data = pd.DataFrame(tmp_data)
# sanity check make sure it looks ok
plt.scatter(data.Easting, data.Northing,8, np.log(data.Au_AVG))
plt.title('Jitarning soil Au results')
plt.colorbar()
plt.xlabel('Easting')
plt.ylabel('Northing')
plt.show()
And finally you need to do a little sanity check to ensure that everything has worked ok.
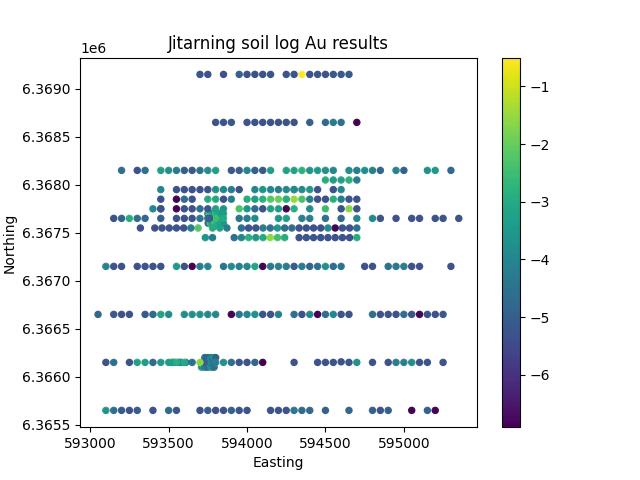
Great we now have a fantastic dataset that we can now go and do something with.
Cheers,
Ben.